Bài viết được tham khảo và tổng hợp lại từ Jayendra’s Blog, xem bài viết gốc ở đây: https://jayendrapatil.com/aws-glue.
Table of contents
Open Table of contents
Giới thiệu
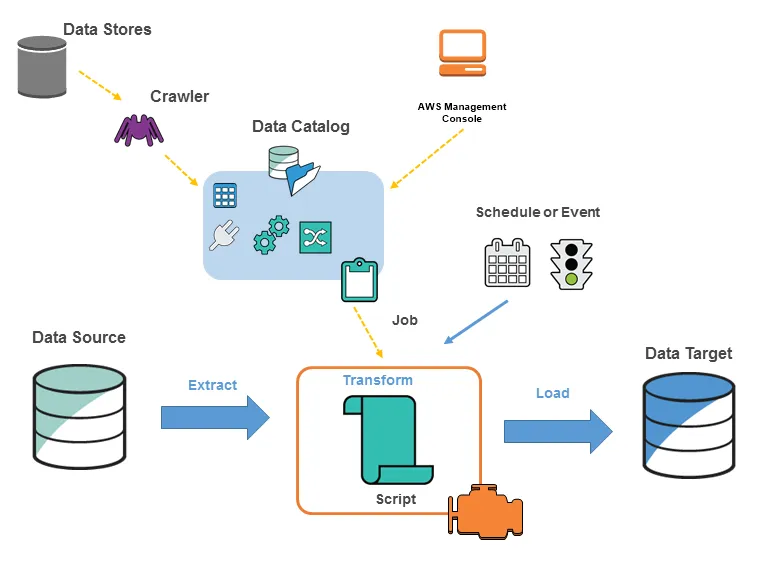
- AWS Glue là một dịch vụ ETL (trích xuất, chuyển đổi và tải dữ liệu) được quản lý hoàn toàn, tự động hóa các bước chuẩn bị dữ liệu tốn thời gian cho phân tích.
- Là dịch vụ không máy chủ và hỗ trợ mô hình thanh toán theo sử dụng, không cần cung cấp hoặc quản lý cơ sở hạ tầng.
- Quản lý việc cung cấp, cấu hình và mở rộng tài nguyên cần thiết để chạy các công việc ETL trong môi trường Apache Spark được quản lý hoàn toàn, có khả năng mở rộng.
- Giúp phân loại, làm sạch, làm giàu và di chuyển dữ liệu giữa các kho dữ liệu và luồng một cách đơn giản và tiết kiệm chi phí.
- Hỗ trợ thiết lập, điều phối và giám sát các luồng dữ liệu phức tạp.
- Tự động hóa phần lớn công việc nặng nhọc như khám phá, phân loại, làm sạch, làm giàu và di chuyển dữ liệu, giúp tiết kiệm thời gian để tập trung vào phân tích dữ liệu.
- Hỗ trợ mã Scala hoặc Python tùy chỉnh và nhập các thư viện tùy chỉnh hoặc tệp Jar vào các công việc ETL của AWS Glue để truy cập các nguồn dữ liệu không được hỗ trợ sẵn bởi AWS Glue.
- Hỗ trợ mã hóa phía máy chủ cho dữ liệu tại chỗ và SSL cho dữ liệu trong quá trình truyền tải.
- Cung cấp các điểm cuối phát triển để chỉnh sửa, gỡ lỗi và kiểm tra mã do nó tạo ra.
- AWS Glue hỗ trợ dữ liệu được lưu trữ trong:
- RDS (Aurora, MySQL, Oracle, PostgreSQL, SQL Server)
- Redshift
- DynamoDB
- S3
- Các cơ sở dữ liệu MySQL, Oracle, Microsoft SQL Server và PostgreSQL trong VPC chạy trên EC2.
- Luồng dữ liệu từ MSK, Kinesis Data Streams, và Apache Kafka.
- Công cụ ETL của Glue để trích xuất, chuyển đổi và tải dữ liệu, có thể tự động tạo mã Scala hoặc Python.
- Glue Data Catalog là kho lưu trữ trung tâm và kho siêu dữ liệu lâu dài để lưu trữ siêu dữ liệu cấu trúc và vận hành cho tất cả tài sản dữ liệu.
- Glue Crawlers quét các kho dữ liệu khác nhau để tự động suy ra lược đồ và cấu trúc phân vùng, điền vào Data Catalog với định nghĩa bảng và thống kê tương ứng.
- AWS Glue Streaming ETL cho phép thực hiện các thao tác ETL trên dữ liệu streaming bằng các công việc chạy liên tục.
- Bộ lập lịch linh hoạt của Glue xử lý phân giải phụ thuộc, giám sát công việc và thử lại.
- Glue Studio cung cấp giao diện đồ họa để tạo các công việc AWS Glue, cho phép định nghĩa luồng dữ liệu từ nguồn, chuyển đổi và đích trong giao diện trực quan, đồng thời tạo mã Apache Spark thay mặt bạn.
- Glue Data Quality giúp giảm nỗ lực chất lượng dữ liệu thủ công bằng cách tự động đo lường và giám sát chất lượng dữ liệu trong hồ dữ liệu và đường ống.
- Glue DataBrew là công cụ chuẩn bị dữ liệu trực quan, giúp các nhà phân tích dữ liệu và nhà khoa học dữ liệu chuẩn bị dữ liệu bằng giao diện trực quan, không cần viết mã. Nó hỗ trợ trực quan hóa, làm sạch và chuẩn hóa dữ liệu trực tiếp từ hồ dữ liệu, kho dữ liệu và cơ sở dữ liệu, bao gồm S3, Redshift, Aurora và RDS.
AWS Glue Data Catalog
- AWS Glue Data Catalog là kho lưu trữ trung tâm và kho siêu dữ liệu lâu dài để lưu trữ siêu dữ liệu cấu trúc và vận hành cho tất cả tài sản dữ liệu.
- Cung cấp kho lưu trữ thống nhất nơi các hệ thống khác nhau có thể lưu trữ và tìm kiếm siêu dữ liệu để theo dõi dữ liệu trong các kho dữ liệu, đồng thời sử dụng siêu dữ liệu đó để truy vấn và chuyển đổi dữ liệu.
- Với một tập dữ liệu, Data Catalog có thể lưu trữ định nghĩa bảng, vị trí vật lý, thêm các thuộc tính liên quan đến kinh doanh và theo dõi cách dữ liệu thay đổi theo thời gian.
- Data Catalog tương thích với Apache Hive Metastore và là giải pháp thay thế trực tiếp cho Hive Metastore cho các ứng dụng Big Data chạy trên EMR.
- Tích hợp sẵn với Athena, EMR và Redshift Spectrum.
- Các định nghĩa bảng sau khi được thêm vào Glue Data Catalog sẽ có sẵn cho ETL và truy vấn trong Athena, EMR và Redshift Spectrum, cung cấp cái nhìn chung về dữ liệu giữa các dịch vụ này.
- Hỗ trợ nhập hàng loạt siêu dữ liệu từ Apache Hive Metastore hiện có bằng cách sử dụng tập lệnh nhập.
- Cung cấp khả năng kiểm tra và quản trị toàn diện, với theo dõi thay đổi lược đồ và kiểm soát truy cập dữ liệu, giúp đảm bảo dữ liệu không bị sửa đổi không phù hợp hoặc chia sẻ ngoài ý muốn.
- Mỗi tài khoản AWS có một AWS Glue Data Catalog cho mỗi vùng.
AWS Glue Crawlers
- AWS Glue Crawler kết nối với kho dữ liệu, duyệt qua danh sách các bộ phân loại ưu tiên để trích xuất lược đồ dữ liệu và các thống kê khác, sau đó điền vào Data Catalog với siêu dữ liệu này.
- Glue Crawlers quét các kho dữ liệu khác nhau để tự động suy ra lược đồ và cấu trúc phân vùng, điền vào Data Catalog với định nghĩa bảng và thống kê tương ứng.
- Có thể lập lịch để Glue Crawlers chạy định kỳ, đảm bảo siêu dữ liệu luôn cập nhật và đồng bộ với dữ liệu gốc.
- Crawlers tự động thêm bảng mới, phân vùng mới vào bảng hiện có và các phiên bản mới của định nghĩa bảng.
Dynamic Frames
- AWS Glue được thiết kế để làm việc với dữ liệu bán cấu trúc và giới thiệu thành phần dynamic frame, có thể sử dụng trong các tập lệnh ETL.
- Dynamic frame là bảng phân tán hỗ trợ dữ liệu lồng nhau như cấu trúc và mảng.
- Mỗi bản ghi là tự mô tả, được thiết kế cho tính linh hoạt lược đồ với dữ liệu bán cấu trúc. Mỗi bản ghi chứa cả dữ liệu và lược đồ mô tả dữ liệu đó.
- Dynamic frame tương tự như Apache Spark dataframe, là một trừu tượng dữ liệu dùng để tổ chức dữ liệu thành hàng và cột, nhưng mỗi bản ghi là tự mô tả nên không cần lược đồ ban đầu.
- Dynamic frames cung cấp tính linh hoạt lược đồ và một tập hợp các chuyển đổi nâng cao được thiết kế đặc biệt cho dynamic frames.
- Có thể chuyển đổi giữa Dynamic frames và Spark dataframes để tận dụng cả các chuyển đổi của AWS Glue và Spark cho các phân tích cần thiết.
AWS Glue Streaming ETL
- AWS Glue cho phép thực hiện các thao tác ETL trên dữ liệu streaming bằng các công việc chạy liên tục.
- Glue Streaming ETL được xây dựng trên công cụ Spark Structured Streaming của Apache, có thể tiếp nhận luồng từ Kinesis Data Streams và Apache Kafka thông qua Amazon Managed Streaming for Apache Kafka.
- Streaming ETL có thể làm sạch và chuyển đổi dữ liệu streaming, sau đó tải vào S3 hoặc kho dữ liệu JDBC.
- Sử dụng Streaming ETL trong AWS Glue để xử lý dữ liệu sự kiện như luồng IoT, luồng nhấp chuột và nhật ký mạng.
Glue Job Bookmark
- Glue Job Bookmark theo dõi dữ liệu đã được xử lý trong lần chạy trước của công việc ETL bằng cách lưu trữ thông tin trạng thái từ lần chạy công việc.
- Job bookmarks giúp Glue duy trì thông tin trạng thái và ngăn chặn việc xử lý lại dữ liệu cũ.
- Job bookmarks hỗ trợ xử lý dữ liệu mới khi chạy lại theo lịch trình.
- Job bookmark bao gồm trạng thái của các thành phần công việc như nguồn, chuyển đổi và đích. Ví dụ: Một công việc ETL có thể đọc các phân vùng mới trong tệp S3. Glue theo dõi phân vùng nào đã được xử lý thành công để tránh xử lý trùng lặp và dữ liệu trùng trong kho dữ liệu đích của công việc.
Glue DataBrew
- Glue DataBrew là công cụ chuẩn bị dữ liệu trực quan, cho phép người dùng làm sạch và chuẩn hóa dữ liệu mà không cần viết mã.
- Là dịch vụ không máy chủ, giúp khám phá và chuyển đổi terabyte dữ liệu thô mà không cần tạo cụm hoặc quản lý cơ sở hạ tầng.
- Giúp giảm thời gian chuẩn bị dữ liệu cho phân tích và học máy (ML).
- Cung cấp 250 chuyển đổi sẵn có để tự động hóa các tác vụ chuẩn bị dữ liệu, như lọc bất thường, chuyển đổi dữ liệu sang định dạng chuẩn và sửa giá trị không hợp lệ.
- Cho phép các nhà phân tích kinh doanh, nhà khoa học dữ liệu và kỹ sư dữ liệu dễ dàng hợp tác để có được thông tin từ dữ liệu thô.