Bài viết được tham khảo và tổng hợp lại từ Jayendra’s Blog, xem bài viết gốc ở đây: https://jayendrapatil.com/aws-redshift.
Table of contents
Open Table of contents
Tổng quan
- Amazon Redshift là dịch vụ kho dữ liệu quy mô petabyte, được quản lý hoàn toàn, nhanh và mạnh mẽ. Redshift là giải pháp kho dữ liệu OLAP dựa trên PostgreSQL.
- Redshift tự động hỗ trợ:
- Thiết lập, vận hành và mở rộng kho dữ liệu, từ cung cấp dung lượng cơ sở hạ tầng.
- Vá lỗi và sao lưu kho dữ liệu, lưu trữ bản sao lưu trong thời gian do người dùng định nghĩa.
- Giám sát các node và ổ đĩa để hỗ trợ khôi phục sau sự cố.
- Giảm đáng kể chi phí kho dữ liệu, đồng thời phân tích nhanh khối lượng dữ liệu lớn.
- Cung cấp khả năng truy vấn nhanh trên structured và semi-structured data, sử dụng các công cụ SQL quen thuộc và công cụ BI thông qua kết nối ODBC/JDBC tiêu chuẩn.
- Sử dụng sao chép và sao lưu liên tục để tăng tính sẵn sàng, cải thiện độ bền dữ liệu, tự động khôi phục từ lỗi node hoặc thành phần.
- Mở rộng hoặc thu hẹp với vài cú nhấp chuột trong AWS Management Console hoặc một lệnh API.
- Phân phối và song song hóa truy vấn trên nhiều tài nguyên vật lý.
- Hỗ trợ VPC, SSL, mã hóa AES-256 và Module Bảo mật Phần cứng (HSMs) để bảo vệ dữ liệu trong quá trình truyền và khi lưu trữ.
- Trước đây, Redshift chỉ hỗ trợ triển khai Single-AZ, các node nằm trong cùng AZ nếu AZ đó hỗ trợ cụm Redshift. Hiện nay, triển khai Multi-AZ đã được hỗ trợ cho một số loại.
- Giám sát: Redshift sử dụng CloudWatch, cung cấp số liệu về sử dụng CPU, lưu trữ, lưu lượng đọc/ghi, và hỗ trợ số liệu tùy chỉnh do người dùng định nghĩa.
- Ghi log: Hỗ trợ ghi log kiểm tra và tích hợp với AWS CloudTrail.
- Redshift có thể dễ dàng kích hoạt sao chép sang vùng thứ hai để khôi phục sau thảm họa.
Redshift Performance
- Xử lý Song song Khối lượng lớn (MPP):
- Tự động phân phối dữ liệu và tải truy vấn trên tất cả các node.
- Dễ dàng thêm node để mở rộng kho dữ liệu, duy trì hiệu năng truy vấn nhanh khi kho dữ liệu phát triển.
- Lưu trữ Dữ liệu theo Cột:
- Sắp xếp dữ liệu theo cột, tối ưu cho kho dữ liệu và phân tích, nơi các truy vấn thường liên quan đến phép tổng hợp trên tập dữ liệu lớn.
- Dữ liệu cột được lưu trữ tuần tự trên phương tiện lưu trữ, giảm đáng kể số lượng I/O, cải thiện hiệu năng truy vấn.
- Nén Nâng cao:
- Lưu trữ cột có thể được nén mạnh hơn so với lưu trữ dựa trên hàng, vì dữ liệu tương tự được lưu trữ tuần tự trên đĩa.
- Sử dụng nhiều kỹ thuật nén, đạt tỷ lệ nén cao so với cơ sở dữ liệu quan hệ truyền thống.
- Không yêu cầu chỉ mục hoặc materialized views, do đó sử dụng ít dung lượng hơn.
- Tự động lấy mẫu dữ liệu và chọn phương pháp nén phù hợp khi dữ liệu được nạp vào bảng rỗng.
- Bộ tối ưu hóa Truy vấn:
- Động cơ thực thi truy vấn Redshift tích hợp bộ tối ưu hóa nhận biết MPP và tận dụng lưu trữ dữ liệu theo cột.
- Bộ nhớ đệm Kết quả:
- Redshift lưu trữ kết quả của một số loại truy vấn trong bộ nhớ trên node chính.
- Khi người dùng gửi truy vấn, Redshift kiểm tra bộ nhớ đệm kết quả; nếu tìm thấy kết quả hợp lệ, Redshift sử dụng kết quả này mà không cần chạy lại truy vấn.
- Bộ nhớ đệm kết quả hoạt động minh bạch với người dùng.
- Mã Biên dịch:
- Node chính phân phối mã được biên dịch tối ưu hóa hoàn toàn trên tất cả các node trong cụm. Việc biên dịch truy vấn giảm chi phí liên quan đến trình thông dịch, tăng tốc độ thực thi, đặc biệt cho các truy vấn phức tạp.
Redshift Architecture
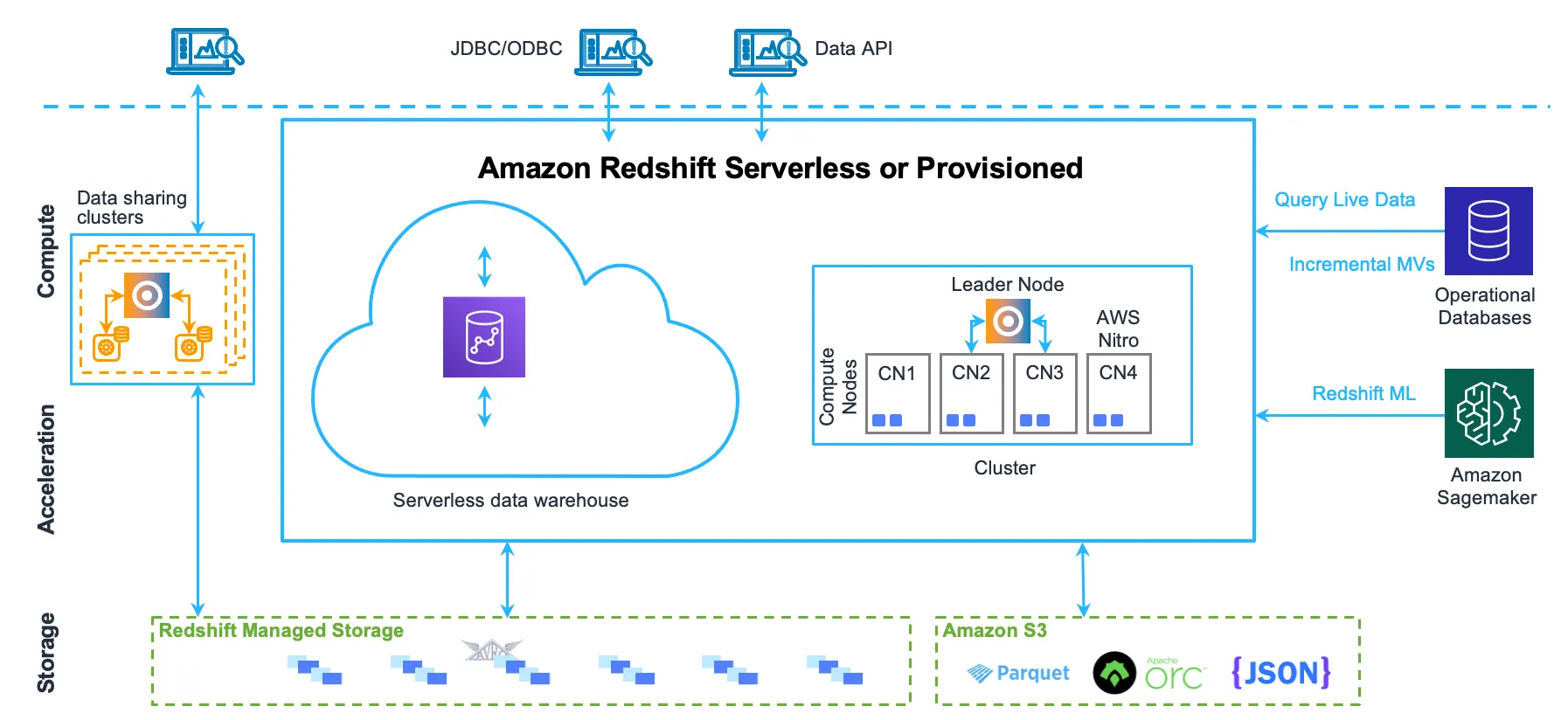
- Cụm (Clusters):
- Thành phần cơ sở hạ tầng cốt lõi của kho dữ liệu Redshift.
- Một cụm bao gồm một hoặc nhiều node tính toán.
- Nếu cụm có từ hai node tính toán trở lên, một node chính bổ sung sẽ điều phối các node tính toán và xử lý giao tiếp bên ngoài.
- Ứng dụng khách chỉ tương tác trực tiếp với node chính; các node tính toán ẩn đối với ứng dụng bên ngoài.
- Node Chính (Leader Node):
- Quản lý giao tiếp với chương trình khách và tất cả giao tiếp với các node tính toán.
- Phân tích cú pháp và phát triển kế hoạch thực thi cho các hoạt động cơ sở dữ liệu.
- Dựa trên kế hoạch thực thi, node chính biên dịch mã, phân phối mã đã biên dịch đến các node tính toán, và gán một phần dữ liệu cho mỗi node tính toán.
- Chỉ phân phối câu lệnh SQL đến các node tính toán khi truy vấn tham chiếu đến bảng được lưu trữ trên các node này; các truy vấn khác chạy độc quyền trên node chính.
- Node Tính toán (Compute Nodes):
- Node chính biên dịch mã cho các thành phần riêng lẻ của kế hoạch thực thi và gán mã cho các node tính toán.
- Các node tính toán thực thi mã đã biên dịch và gửi kết quả trung gian về node chính để tổng hợp cuối cùng.
- Mỗi node tính toán có CPU, bộ nhớ và lưu trữ đĩa gắn kèm riêng, được xác định bởi loại node.
- Khi khối lượng công việc tăng, có thể tăng dung lượng tính toán và lưu trữ của cụm bằng cách tăng số lượng node, nâng cấp loại node, hoặc cả hai.
- Phân đoạn Node (Node Slices):
- Một node tính toán được chia thành các phân đoạn (slices).
- Mỗi phân đoạn được cấp một phần bộ nhớ và dung lượng đĩa của node, xử lý một phần khối lượng công việc được gán cho node.
- Node chính quản lý việc phân phối dữ liệu đến các phân đoạn và phân bổ khối lượng công việc cho các truy vấn hoặc hoạt động cơ sở dữ liệu khác. Các phân đoạn hoạt động song song để hoàn thành thao tác.
- Số lượng phân đoạn mỗi node được xác định bởi kích thước node của cụm.
- Khi tạo bảng, có thể chỉ định một cột làm khóa phân phối (distribution key). Khi bảng được nạp dữ liệu, các hàng được phân phối đến các phân đoạn node theo khóa phân phối, giúp Redshift sử dụng xử lý song song để nạp dữ liệu và thực thi truy vấn hiệu quả.
- Lưu trữ Quản lý (Managed Storage):
- Dữ liệu kho dữ liệu được lưu trữ trong tầng lưu trữ riêng Redshift Managed Storage (RMS).
- RMS cho phép mở rộng lưu trữ lên đến petabyte sử dụng lưu trữ S3.
- RMS tách biệt chi phí tính toán và lưu trữ, cho phép định cỡ cụm chỉ dựa trên nhu cầu tính toán.
- RMS tự động sử dụng lưu trữ cục bộ dựa trên SSD hiệu năng cao làm bộ đệm cấp 1.
- Tận dụng các tối ưu hóa như nhiệt độ khối dữ liệu, tuổi khối dữ liệu và mô hình khối lượng công việc để cung cấp hiệu năng cao, đồng thời tự động mở rộng lưu trữ sang S3 khi cần mà không yêu cầu hành động.
Redshift Serverless
- Redshift Serverless là tùy chọn không máy chủ của Redshift, giúp chạy và mở rộng phân tích trong vài giây mà không cần thiết lập hoặc quản lý cơ sở hạ tầng kho dữ liệu.
- Tự động cung cấp và mở rộng thông minh dung lượng kho dữ liệu để mang lại hiệu năng cao cho khối lượng công việc đòi hỏi cao và không thể dự đoán.
- Giúp người dùng dễ dàng lấy thông tin từ dữ liệu bằng cách nạp và truy vấn dữ liệu trong kho dữ liệu.
- Hỗ trợ tính năng Concurrency Scaling, cho phép hỗ trợ số lượng người dùng và truy vấn đồng thời không giới hạn với hiệu năng truy vấn nhanh ổn định.
- Khi Concurrency Scaling được kích hoạt, Redshift tự động thêm dung lượng cụm khi cụm gặp tình trạng xếp hàng truy vấn.
- Redshift Serverless đo lường dung lượng kho dữ liệu bằng Redshift Processing Units (RPUs), là tài nguyên được sử dụng để xử lý khối lượng công việc.
- Hỗ trợ workgroups và namespaces để cách ly khối lượng công việc và quản lý các tài nguyên khác nhau.
Redshift Single vs Multi-Node Cluster
- Single Node:
- Cấu hình đơn node giúp bắt đầu nhanh chóng, tiết kiệm chi phí và có thể mở rộng sang cấu hình đa node khi nhu cầu tăng.
- Multi-Node:
- Yêu cầu một node chính quản lý kết nối khách hàng và nhận truy vấn, cùng với hai hoặc nhiều node tính toán lưu trữ dữ liệu và thực hiện truy vấn/tính toán.
- Node Chính:
- Được cung cấp tự động, không tính phí.
- Nhận truy vấn từ ứng dụng khách, phân tích cú pháp truy vấn, phát triển kế hoạch thực thi, điều phối thực thi song song với các node tính toán, tổng hợp kết quả trung gian và trả kết quả về ứng dụng khách.
- Node Tính toán:
- Có thể chứa từ 1 đến 128 node, tùy thuộc vào loại node.
- Thực thi các bước trong kế hoạch thực thi, truyền dữ liệu giữa các node để phục vụ truy vấn.
- Kết quả trung gian được gửi về node chính để tổng hợp trước khi trả về ứng dụng khách.
- Hỗ trợ loại node Dense Storage (DS) (sử dụng HDD cho kho dữ liệu lớn với chi phí thấp) hoặc Dense Compute (DC) (sử dụng CPU nhanh, RAM lớn và SSD cho hiệu năng cao).
- Không cho phép truy cập trực tiếp vào node tính toán.
Redshift Multi-AZ
- Triển khai Multi-AZ chạy kho dữ liệu đồng thời trên nhiều AZ của AWS, tiếp tục hoạt động trong các kịch bản lỗi không lường trước.
- Được quản lý như một kho dữ liệu duy nhất với một điểm cuối, không yêu cầu thay đổi ứng dụng.
- Hỗ trợ yêu cầu tính sẵn sàng cao, giảm thời gian khôi phục, đảm bảo dung lượng tự động khôi phục, phù hợp cho các ứng dụng phân tích quan trọng cần mức độ sẵn sàng và khả năng phục hồi cao trước lỗi AZ.
- Hỗ trợ RPO = 0 (dữ liệu luôn cập nhật trong trường hợp lỗi) và RTO dưới một phút.
Redshift Availability & Durability
- Redshift sao chép dữ liệu trong cụm kho dữ liệu và liên tục sao lưu dữ liệu lên S3 (độ bền 11 9’s).
- Sao chép dữ liệu của mỗi ổ đĩa sang các node khác trong cụm.
- Tự động phát hiện và thay thế ổ đĩa hoặc node bị lỗi.
- Cụm RA3 và Redshift Serverless không bị ảnh hưởng tương tự vì dữ liệu được lưu trữ trên S3, ổ đĩa cục bộ chỉ dùng làm bộ đệm.
- Nếu ổ đĩa lỗi:
- Cụm vẫn sẵn sàng, truy vấn tiếp tục với độ trễ tăng nhẹ trong khi Redshift xây dựng lại ổ đĩa từ bản sao dữ liệu trên các ổ đĩa khác trong node.
- Cụm đơn node không hỗ trợ sao chép dữ liệu, cần khôi phục từ snapshot trên S3.
- Nếu node lỗi:
- Tự động cung cấp node mới và bắt đầu khôi phục dữ liệu từ các ổ đĩa khác trong cụm hoặc từ S3.
- Ưu tiên khôi phục dữ liệu được truy vấn thường xuyên để các truy vấn phổ biến nhanh chóng đạt hiệu năng.
- Cụm không sẵn sàng cho truy vấn và cập nhật cho đến khi node thay thế được cung cấp và thêm vào cụm.
- Nếu AZ của cụm Redshift lỗi:
- Cụm không sẵn sàng cho đến khi nguồn điện và mạng được khôi phục cho AZ.
- Dữ liệu của cụm được bảo toàn và có thể sử dụng khi AZ sẵn sàng.
- Có thể khôi phục cụm từ snapshot hiện có sang AZ mới trong cùng vùng.
Redshift Backup & Restore
- Redshift duy trì ít nhất ba bản sao dữ liệu: bản gốc, bản sao trên node tính toán, và bản sao lưu trên S3.
- Sao chép toàn bộ dữ liệu trong cụm khi nạp dữ liệu và liên tục sao lưu lên S3.
- Mặc định, kích hoạt sao lưu tự động với thời gian lưu trữ 1 ngày, có thể mở rộng tối đa 35 ngày.
- Có thể tắt sao lưu tự động bằng cách đặt thời gian lưu trữ là 0.
- Hỗ trợ sao chép không đồng bộ snapshot sang S3 ở vùng khác để khôi phục sau thảm họa.
- Chỉ sao lưu dữ liệu đã thay đổi.
- Khôi phục sao lưu sẽ cung cấp một cụm kho dữ liệu mới.
Redshift Scalability
- Redshift cho phép mở rộng cụm bằng:
- Tăng loại phiên bản node (mở rộng dọc).
- Tăng số lượng node (mở rộng ngang).
- Thay đổi mở rộng thường được áp dụng trong maintenance window hoặc có thể áp dụng ngay lập tức.
- Quy trình mở rộng:
- Cụm hiện tại vẫn sẵn sàng cho hoạt động đọc, trong khi cụm kho dữ liệu mới được tạo trong quá trình mở rộng.
- Dữ liệu từ node tính toán trong cụm hiện tại được di chuyển song song sang node tính toán trong cụm mới.
- Khi cụm mới sẵn sàng, cụm hiện tại tạm thời không sẵn sàng trong khi bản ghi tên chuẩn (canonical name record) của cụm hiện tại được chuyển sang cụm mới.
Redshift Security
- Hỗ trợ mã hóa dữ liệu tại chỗ và trong quá trình truyền (encryption at rest và in transit).
- Hỗ trợ kiểm soát truy cập dựa trên vai trò (RBAC). Kiểm soát truy cập cấp hàng cho phép gán một hoặc nhiều vai trò cho người dùng và gán quyền hệ thống/đối tượng theo vai trò.
- Hỗ trợ Hàm Người dùng Định nghĩa Lambda (UDFs) để tích hợp với các nhà cung cấp như Protegrity, cho phép mã hóa, che giấu dữ liệu (data masking), nhận diện hoặc bỏ nhận diện dữ liệu, bảo vệ hoặc bỏ bảo vệ dữ liệu nhạy cảm dựa trên quyền và nhóm của người dùng tại thời điểm truy vấn.
- Hỗ trợ Single Sign-On SSO và tích hợp với các nhà cung cấp danh tính tuân thủ SAML.
- Hỗ trợ xác thực đa yếu tố (MFA) để tăng cường bảo mật khi xác thực với cụm Redshift.
- Hỗ trợ mã hóa cụm không mã hóa bằng KMS. Tuy nhiên, không thể kích hoạt mã hóa HSM bằng cách sửa đổi cụm; thay vào đó, cần tạo cụm mới mã hóa HSM và di chuyển dữ liệu sang cụm mới.
- Định tuyến VPC Nâng cao buộc tất cả lưu lượng COPY và UNLOAD giữa cụm và kho dữ liệu đi qua VPC.
Advanced Topics
Xem chi tiết ở đây:
Redshift vs EMR vs RDS
- RDS:
- Lý tưởng cho dữ liệu có cấu trúc và chạy cơ sở dữ liệu quan hệ truyền thống, giảm tải quản trị cơ sở dữ liệu.
- Phù hợp cho xử lý giao dịch trực tuyến (OLTP) và báo cáo/phân tích.
- Redshift:
- Lý tưởng cho khối lượng dữ liệu có cấu trúc lớn cần được lưu trữ và truy vấn bằng SQL tiêu chuẩn và công cụ BI hiện có.
- Phù hợp cho khối lượng công việc phân tích và báo cáo trên tập dữ liệu rất lớn, tận dụng quy mô và tài nguyên của nhiều node, cung cấp cải tiến so với RDS.
- Ngăn chặn xử lý báo cáo và phân tích làm ảnh hưởng đến hiệu năng của khối lượng công việc OLTP.
- EMR:
- Lý tưởng cho xử lý và chuyển đổi dữ liệu không cấu trúc hoặc bán cấu trúc để đưa vào Redshift.
- Phù hợp cho tập dữ liệu tạm thời, không lưu trữ lâu dài.